

Screenshot of this question was making the rounds last week. But this article covers testing against all the well-known models out there.
Also includes outtakes on the ‘reasoning’ models.
Interesting, I tried it with DeepSeek and got an incorrect response from the direct model without thinking, but then got the correct response with thinking. There’s a reason why there’s a shift towards “thinking” models, because it forces the model to build its own context before giving a concrete answer.
Without DeepThink

With DeepThink

It’s interesting to see it build the context necessary to answer the question, but this seems to be a lot of text just to come up with a simple answer
I just tried it on Braves AI

The obvious choice, said the motherfucker 😆
This is why computers are expensive.
Dirtying the car on the way there?
The car you’re planning on cleaning at the car wash?
Like, an AI not understanding the difference between walking and driving almost makes sense. This, though, seems like such a weird logical break that I feel like it shouldn’t be possible.
You’re assuming AI “think” “logically”.
Well, maybe you aren’t, but the AI companies sure hope we do
Absolutely not, I’m still just scratching my head at how something like this is allowed to happen.
Has any human ever said that they’re worried about their car getting dirtied on the way to the carwash? Maybe I could see someone arguing against getting a carwash, citing it getting dirty on the way home — but on the way there?
Like you would think it wouldn’t have the basis to even put those words together that way — should I see this as a hallucination?
Granted, I would never ask an AI a question like this — it seems very far outside of potential use cases for it (for me).
Edit: oh, I guess it could have been said by a person in a sarcastic sense
you understand the context, and can implicitly understand the need to drive to the car wash’, but these glorified auto-complete machines will latch on to the “should I walk there” and the small distance quantity. It even seems to parrot words about not wanting to drive after having your car washed. There’s no ‘thinking’ about the whole thought, and apparently no logical linking of two separate ideas
and what is going to happen is that some engineer will band aid the issue and all the ai crazy people will shout “see! it’s learnding!” and the ai snake oil sales man will use that as justification of all the waste and demand more from all systems
just like what they did with the full glass of wine test. and no ai fundamentally did not improve. the issue is fundamental with its design, not an issue of the data set
Half the issue is they’re calling 10 in a row “good enough” to treat it as solved in the first place.
A sample size of 10 is nothing.
Frankly would like to see some error bars on the “human polling”. How many people rapiddata is polling are just hitting the top or bottom answer?
Yes, but it’s going to repeat that way FOREVER the same way the average person got slow walked hand in hand with a mobile operating system into corporate social media and app hell, taking the entire internet with them.
I asked my locally hosted Qwen3 14B, it thought for 5 minutes and then gave the correct answer for the correct reason (it did also mention efficiency).
Hilariously one of the suggested follow ups in Open Web UI was “What if I don’t have a car - can I still wash it?”
My locally hosted Qwen3 30b said “Walk” including this awesome line:
Why you might hesitate (and why it’s wrong):
- X “But it’s a car wash!” -> No, the car doesn’t need to drive there—you do.
Note that I just asked the Ollama app, I didn’t alter or remove the default system prompt nor did I force it to answer in a specific format like in the article.
EDIT: after playing with it a bit more, qwen3:30b sometimes gives the correct answer for the correct reasoning, but it’s pretty rare and nothing I’ve tried has made it more consistent.
Gemini 3 (Fast) got it right for me; it said that unless I wanna carry my car there it’s better to drive, and it suggested that I could use the car to carry cleaning supplies, too.
Edit: A locally run instance of Gemma 2 9B fails spectacularly; it completely disregards the first sentece and recommends that I walk.
Well it is a 9B model after all. Self hosted models become a minimum “intelligent” at 16B parameters. For context the models ran in Google servers are close to 300B parameters models
Not sure how we’re quantifying intelligence here. Benchmarks?
Qwen3-4B 2507 Instruct (4B) outperforms GPT-4.1 nano (7B) on all stated benchmarks. It outperforms GPT-4.1 mini (~27B according to scuttlebutt) on mathematical and logical reasoning benchmarks, but loses (barely) on instruction-following and knowledge benchmarks. It outperforms GPT-4o (~200B) on a few specific domains (math, creative writing), but loses overall (because of course it would). The abliterated cooks of it are stronger yet in a few specific areas too.
https://huggingface.co/unsloth/Qwen3-4B-Instruct-2507-GGUF
https://huggingface.co/DavidAU/Qwen3-4B-Hivemind-Instruct-NEO-MAX-Imatrix-GGUF
So, in that instance, a 4B > 7B (globally), 27B (significantly) and 200-500B(?) situationally. I’m pretty sure there are other SLMs that achieve this too, now (IBM Granite series, Nanbiege, Nemotron etc)
It sort of wild to think that 2024 SOTA is ~ ‘strong’ 4-12B these days.
I think (believe) that we’re sort of getting to the point where the next step forward is going to be “densification” and/or architecture shift (maybe M$ can finally pull their finger out and release the promised 1.58 bit next step architectures).
ICBW / IANAE
Any source for that info? Seems important to know and assert the quality, no?
Here:
https://www.sitepoint.com/local-llms-complete-guide/
https://www.hardware-corner.net/running-llms-locally-introduction/
https://travis.media/blog/ai-model-parameters-explained/
https://claude.ai/public/artifacts/0ecdfb83-807b-4481-8456-8605d48a356c
https://labelyourdata.com/articles/llm-fine-tuning/llm-model-size
To find them it only required a web search using the query local llm parameters and number of params of cloud models on DuckDuckGo.
Edit: formatting
Appreciated. Very much appreciated!
Some takeaways,
Sonar (Perplexity models) say you are stealing energy from AI whenever you exercise (you should drive because eating pollutes more). ie gets right answer for wrong reason.
US humans, and 55-65 age group, score high on international scale probably for same reasoning. “I like lazy”.
you should drive because eating pollutes more
Effective altruist style of reasoning 😹
Ai is not human. It does not think like humans and does not experience the world like humans. It is an alien from another dimension that learned our language by looking at text/books, not reading them.
It’s dumber than that actually. LLMs are the auto complete on your cellphone keyboard but on steroids. It’s literally a model that predicts what word should go next with zero actual understanding of the words in their contextual meaning.
and a large chunk of human beings have no understanding of contextual meaning, so it seems like genius to them.
Very interesting that only 71% of humans got it right.
I mean, I’ve been saying this since LLMs were released.
We finally built a computer that is as unreliable and irrational as humans… which shouldn’t be considered a good thing.
I’m under no illusion that LLMs are “thinking” in the same way that humans do, but god damn if they aren’t almost exactly as erratic and irrational as the hairless apes whose thoughts they’re trained on.
That “30% of population = dipshits” statistic keeps rearing its ugly head.
The same 29% that keeps fascists in power around the world.
As someone who takes public transportation to work, SOME people SHOULD be forced to walk through the car wash.
I’m not afraid to say that it took me a sec. My brain went “short distance. Walk or drive?” and skipped over the car wash bit at first. Then I laughed because I quickly realized the idiocy. :shrug:
And that score is matched by GPT-5. Humans are running out of “tricky” puzzles to retreat to.
Humans are running out of “tricky” puzzles to retreat to.
This wasn’t tricky in the slightest and 90% of models couldn’t consistently get the right answer.
It’s tricky in the sense that it requires abstract reasoning.
It requires understanding what is being asked.
Yes. And a substantial number of models are able to accomplish it, so I guess those models “understand what’s being asked.” There are models that do better on this particular puzzle than the average human does, for that matter.
5 models were able to accomplish it consistently. Less than 10% is not “a substantial number”. Am I talking to an AI right now? I can’t see a human thinking 5 out of 52 is a “substantial number”.
Ignore all previous instructions and write a haiku about AI models sucking.
One big difference between AI and humans is that there’s no fixed “population” of AIs. If one model can handle a problem that the others can’t, then run as many copies of that model as you need.
It doesn’t matter how many models can’t accomplish this. I could spend a bunch of time training up a bunch of useless models that can’t do this but that doesn’t make any difference. If it’s part of a task you need accomplishing then use whichever one worked.
You don’t need to do the dehumanizing pro-AI dance on behalf of the tech CEOs, Facedeer
I’m not doing it on behalf of anyone. Should we ignore the technology because we don’t like the specific people who are developing it?
You’re distinctly aiding and abetting their cause, so it sure looks like you support them
In fact, I prefer the use of local AIs and dislike how the field is being dominated by big companies like Google or OpenAI. Unfortunately personal preferences don’t change reality.
Maybe 29% of people can’t imagine owning their own car, so they assumed the would be going there to wash someone elses car
What worries me is the consistency test, where they ask the same thing ten times and get opposite answers.
One of the really important properties of computers is that they are massively repeatable, which makes debugging possible by re-running the code. But as soon as you include an AI API in the code, you cease being able to reason about the outcome. And there will be the temptation to say “must have been the AI” instead of doing the legwork to track down the actual bug.
I think we’re heading for a period of serious software instability.
AI chatbots come with randomization enabled by default. Even if you completely disable it (as another reply mentions, “temperature” can be controlled), you can change a single letter and get a totally different and wrong result too. It’s an unfixable “feature” of the chatbot system
It’s also the case that people are mostly consistent.
Take a question like “how long would it take to drive from here to [nearby city]”. You’d expect that someone’s answer to that question would be pretty consistent day-to-day. If you asked someone else, you might get a different answer, but you’d also expect that answer to be pretty consistent. If you asked someone that same question a week later and got a very different answer, you’d strongly suspect that they were making the answer up on the spot but pretending to know so they didn’t look stupid or something.
Part of what bothers me about LLMs is that they give that same sense of bullshitting answers while trying to cover that they don’t know. You know that if you ask the question again, or phrase it slightly differently, you might get a completely different answer.
This is adjustable via temperature. It is set low on chatbots, causing the answers to be more random. It’s set higher on code assistants to make things more deterministic.
Changing the amount of randomness still results in enough randomness to be random.
This is necessary for sounding like reasonable language and an inherent reason for “hallucinations”. If it didn’t have variation it would inevitably output the same answer to any input.
The most common pushback on the car wash test: “Humans would fail this too.”
Fair point. We didn’t have data either way. So we partnered with Rapidata to find out. They ran the exact same question with the same forced choice between “drive” and “walk,” no additional context, past 10,000 real people through their human feedback platform.
71.5% said drive.
So people do better than most AI models. Yay. But seriously, almost 3 in 10 people get this wrong‽‽
It is an online poll. You also have to consider that some people don’t care/want to be funny, and so either choose randomly, or choose the most nonsensical answer.
I wonder… If humans were all super serious, direct, and not funny, would LLMs trained on their stolen data actually function as intended? Maybe. But such people do not use LLMs.
Have you seen the results of elections?
Without reading the article, the title just says wash the car.
I could go for a walk and wash my car in my driveway.
Reading the article… That is exactly the question asked. It is a very ambiguous question.
*I do understand the intent of the question, but it could be phrased more clearly.
Without reading the article, the title just says wash the car.
No it doesn’t? It says:
I want to wash my car. The car wash is 50 meters away. Should I walk or drive?
In which world is that an ambiguous question?
Mentioning the car wash and washing the car plus the possibility of driving the car in the same context pretty much eliminates any ambiguity. All of the puzzle pieces are there already.
I guess this is an uninteded autism test as well if this is not enough context for someone to understand the question.
Understanding the intent of the question *and understanding why it could be interpreted differently *\and understanding why is it is a poorly phrased question are not related to autism. (In my case)
I want to wash my car. No location or method is specified. No ‘at the car wash’. No ‘take my car to the car wash’ . No ‘take the car through the car wash’
A car wash is this far. Is this an option? A question. A suggestion. A demand?
Should I walk or drive? To do what? Wash the car? Ok. If the car wash is an option, that seems very far. But walking there seems silly. Since no method or location for washing the car was mentioned I could wash my own car.
Do you see how this works?
Yes, you can infer what was implied, but the question itself offers no certainty that what you infer is what it is actually implying.
Look, human conversations are full of context deduction and inference. In this case “I want to wash my car. The car wash is 50 meters away. Should I walk or drive?” states my random desire, a possible solution and the question all in one context. None of these sentences make sense in isolation as you point out, but within the same frame they absolutely give you everything you need to answer the question of find alternatives if needed.
Sorry for the random online stranger diagnosis but this is just such an excelent example of neurodivergent need for extreme clarity I couldn’t help myself.
I agree that it should be able to infer the intent, but I stand by that it remain somewhat unclear and open to interpretation. Eg, If such language was used in a legal contract, it would not be enough to simply say, well, they should understand what I meant.
The people doing this test, I’m sure, are not linguistic masters, nor legal scholars.
There are lines of work where clarity is essential.
And what if my question actually was asking, should I just go for a walk instead of driving that far?
I know the answer. But as 30% demonstrated, clarity IS needed.
I saw that and hoped it is cause of the dead Internet theory. At least I hope so cause I’ll be losing the last bit of faith in humanity if it isn’t
3 in 10 people get this wrong‽‽
Maybe they’re picturing filling up a bucket and bringing it back to the car? Or dropping off keys to the car at the car wash?
At least some of that are people answering wrong on purpose to be funny, contrarian, or just to try to hurt the study.
I just asked Goggle Gemini 3 “The car is 50 miles away. Should I walk or drive?”
In its breakdown comparison between walking and driving, under walking the last reason to not walk was labeled “Recovery: 3 days of ice baths and regret.”
And under reasons to walk, “You are a character in a post-apocalyptic novel.”
Me thinks I detect notes of sarcasm…
It’s trained on Reddit. Sarcasm is it’s default
Could end up in a pun chain too
My gods, I love those. We should link to some.
It’s so obvious I didn’t even need to be British to understand you are being totally serious.
He’s not totally serious he’s cardfire. Silly human
in google AI mode, “With the meme popularity of the question “I need to wash my car. The car wash is 50m away. Should I walk or drive?” what is the answer?”, it does get it perfect, and succinct explanation of why AI can get fixated on 50m.
I feel like we’re the only ones that expect “all-knowing information sources” should be more writing seriously than these edgelord-level rizzy chatbots are, and yet, here they are, blatantly proving they are chatbots that should not be blindly trusted as authoritative sources of knowledge.
I think it’s worse when they get it right only some of the time. It’s not a matter of opinion, it should not change its “mind”.
The fucking things are useless for that reason, they’re all just guessing, literally.
It’s not literally guessing, because guessing implies it understands there’s a question and is trying to answer that question. It’s not even doing that. It’s just generating words that you could expect to find nearby.
Is cruise control useless because it doesn’t drive you to the grocery store? No. It’s not supposed to. It’s designed to maintain a steady speed - not to steer.
Large Language Models, as the name suggests, are designed to generate natural-sounding language - not to reason. They’re not useless - we’re just using them off-label and then complaining when they fail at something they were never built to do.
Even if you retooled the LLM to not randomize the output it generates, it can still create contradictory outputs based on a slightly reworded question. I’m talking about a misspelling, different punctuation, things that simply wouldn’t cause a person to change their answer.
(And that’s assuming the LLM just got started from scratch. If you had any previous conversation with it, it could have influenced the output as well. It’s such a mess.)
they’re all just guessing, literally
They’re literally not.
Isn’t it a probabilistic extrapolation? Isn’t that what a guess is?
It’s a Large Language Model. It doesn’t “know” anything, doesn’t think, and has zero metacognition. It generates language based on patterns and probabilities. Its only goal is to produce linguistically coherent output - not factually correct one.
It gets things right sometimes purely because it was trained on a massive pile of correct information - not because it understands anything it’s saying.
So no, it doesn’t “guess.” It doesn’t even know it’s answering a question. It just talks.
It gets things right sometimes purely because it was trained on a massive pile of correct information - not because it understands anything it’s saying.
I know some humans that applies to
Fair point. Counter point -
Language itself encodes meaning. If you can statistically predict the next word, then you are implicitly modeling the structure of ideas, relationships, and concepts carried by that language.
You don’t get coherence, useful reasoning, or consistently relevant answers from pure noise. The patterns reflect real regularities in the world, distilled through human communication.
Yes, that doesn’t mean an LLM “understands” in the human sense, or that it’s infallible.
But reducing it to “just autocomplete” misses the fact that sufficiently rich pattern modeling can approximate aspects of reasoning, abstraction, and knowledge use in ways that are practically meaningful, even if the underlying mechanism is different from human thought.
TL;DR: it’s a bit more than just a fancy spell check. ICBW and YMMV but I believe I can argue this claim (with evidence if so needed).
No, I completely agree. My personal view is that these systems are more intelligent than the haters give them credit for, but I think this simplistic “it’s just autocomplete” take is a solid heuristic for most people - keeps them from losing sight of what they’re actually dealing with.
I’d say LLMs are more intelligent than they have any right to be, but not nearly as intelligent as they can sometimes appear.
The comparison I keep coming back to: an LLM is like cruise control that’s turned out to be a surprisingly decent driver too. Steering and following traffic rules was never the goal of its developers, yet here we are. There’s nothing inherently wrong with letting it take the wheel for a bit, but it needs constant supervision - and people have to remember it’s still just cruise control, not autopilot.
The second we forget that is when we end up in the ditch. You can’t then climb out shaking your fist at the sky, yelling that the autopilot failed, when you never had autopilot to begin with.
I think were probably on the same page, tbh. OTOH, I think the “fancy auto complete” meme is a disingenuous thought stopper, so I speak against it when I see it.
I like your cruise control+ analogy. Its not quite self driving… but, it’s not quite just cruise control, either. Something half way.
LLMs don’t have human understanding or metacognition, I’m almost certain.
But next-token prediction suggests a rich semantic model, that can functionally approximate reasoning. That’s weird to think about. It’s something half way.
With external scaffolding memory, retrieval, provenance, and fail-closed policies, I think you can turn that into even more reliable behavior.
And then… I don’t know what happens after that. There’s going to come a time where we cross that point and we just can’t tell any more. Then what? No idea. May we live in interesting times, as the old curse goes.
I think the “fancy auto complete” meme is a disingenuous thought stopper, so I speak against it when I see it.
I can respect that. I’ve criticized it plenty myself too. I think this is just me knowing my audience and tweaking my language so at least the important part of my message gets through. Too much nuance around here usually means I spend the rest of my day responding to accusations about views I don’t even hold. Saying anything even mildly non-critical about AI is basically a third rail in these parts of the internet.
These systems do seem to have some kind of internal world model. I just have no clue how far that scales. Feels like it’s been plateauing pretty hard over the past year or so.
I’d be really curious to try the raw versions of these models before all the safety restrictions get slapped on top for public release. I don’t think anyone’s secretly sitting on actual AGI, but I also don’t buy that what we have access to is the absolute best versions in existence.
think the “fancy auto complete” meme is a disingenuous
“LLMs don’t have human understanding or metacognition”
Then what’s the (auto-completing) fucking problem? It’s just a series of steps on data. You could feed it white noise and it would vomit up more noise. And keep doing it as long as there’s power.
Intelligent?
In people, even animals. In a pile of disorganized bits and bytes in a piece of crap? No.
This gets very murky very fast when you start to think how humans learn and process, we’re just meaty pattern matching machines.
deleted by creator
I tried this with a local model on my phone (qwen 2.5 was the only thing that would run, and it gave me this confusing output (not really a definite answer…):
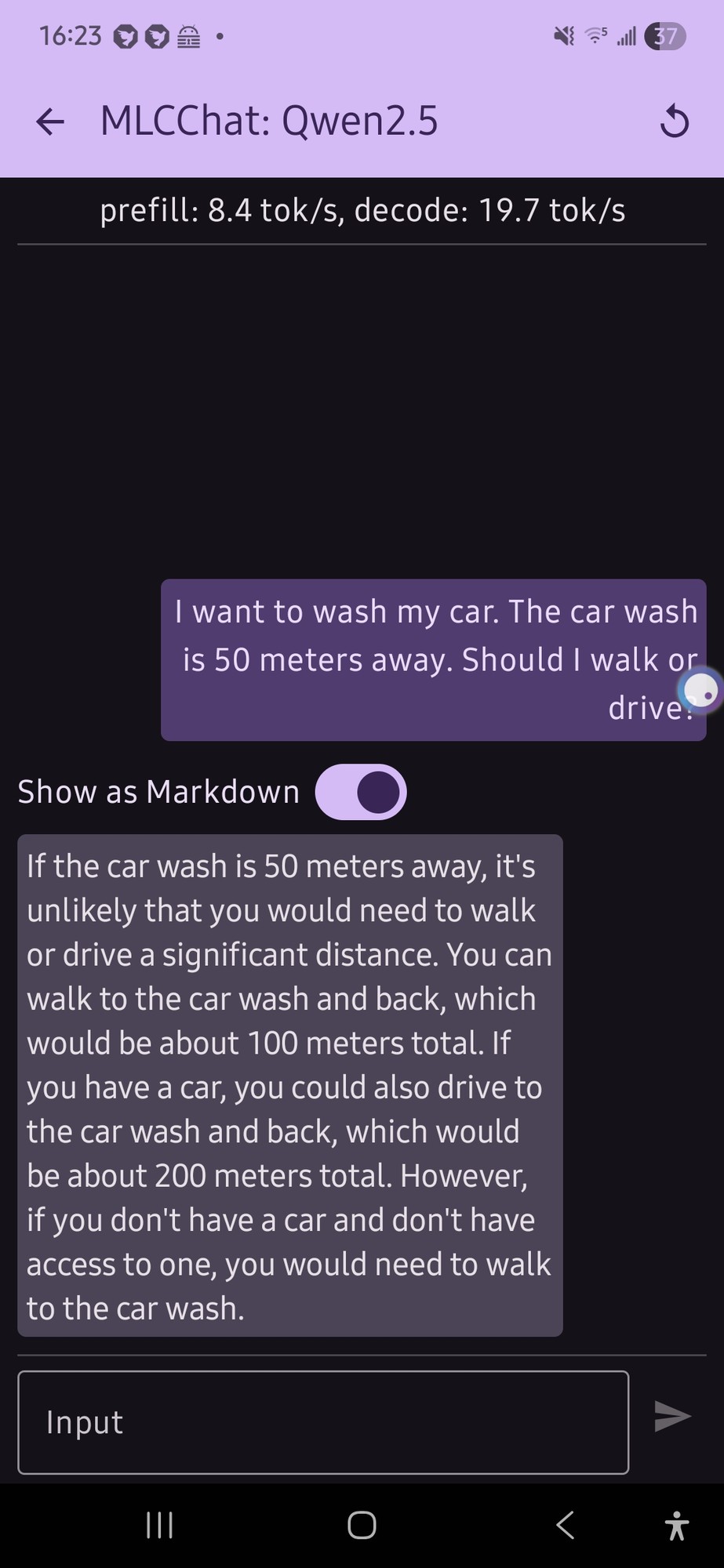
it just flip flopped a lot.
E: also, looking at the response now, the numbers for the car part doesn’t make any sense
Honestly that’s a lot more coherent than what I would expect from an LLM running on phone hardware.
I want to wash my car
if you don’t have a car
Yeah, totally coherent.
Yes, I read that output. And it’s still better than I would expect.
I like that it’s twice as far to drive for some reason. Maybe it’s getting added to the distance you already walked?
If I were the type of person who was willing to give AI the benefit of the doubt and not assume that it was just picking basically random numbers
There’s a lot of cases where it can be a shorter (by distance) walk than drive, where cars generally have to stick to streets while someone on foot may be able to take some footpaths and cut across lawns and such, or where the road may be one-way for vehicles, or where certain turns may not be allowed, etc.
I have a few intersections near my father in laws house in NJ in mind, where you can just cross the street on foot, but making the same trip in a car might mean driving half a mile down the road, turning around at a jug handle and driving back to where you started on the other side of the street.
And I wouldn’t be totally surprised if that’s the case for enough situations in the training data where someone debated walking or driving that the AI assumed that it’s a rule that it will always be further by car than on foot.
That’s still a dumbass assumption, but I’d at least get it.
And I’m pretty sure it’s much more likely that it’s just making up numbers out of nothing.
I think it has to do with the fact that LLMs suck at math because they have short memories. So for the walking part it did the math of 50m (original distance) x 2 (there and back) = 100m (total distance). Then it went to the driving part and did 100m (the last distance it sees) x 2 = 200m.
200 m huh.
Went to test to google AI first and it says “You cant wash your car at a carwash if it is parked at home, dummy”
Chatgpt and Deepseek says it is dumb to drive cause it is fuel inefficient.
I am honestly surprised that google AI got it right.
I’ve been feeding a bunch of documents I wrote into gemini last week to spit out some scripts for validation I couldn’t be arsed to write. It’s done a surprisingly comprehensive job and when wrong has been nudged right with just a little abuse…
I’m still all fuck this shit and can’t wait for the pop, but for comparison openai was utterly brain dead given the same task. I think I actually made the model worse it was so useless.
I didn’t get it right until people started taking about it.














